
3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产
3B小模型,编程得分比肩Opus 4.5,神秘模型引发热议,原是国产最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
来自主题: AI技术研报
10518 点击 2026-06-18 15:30
 搜索
搜索
最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

周四晚上,我在床上举着 iPhone Air,在 Siri 对话框里打下了一个从来没问过的问题: Siri, what do you think of me?(Siri,你觉得我怎么样?)

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气:

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
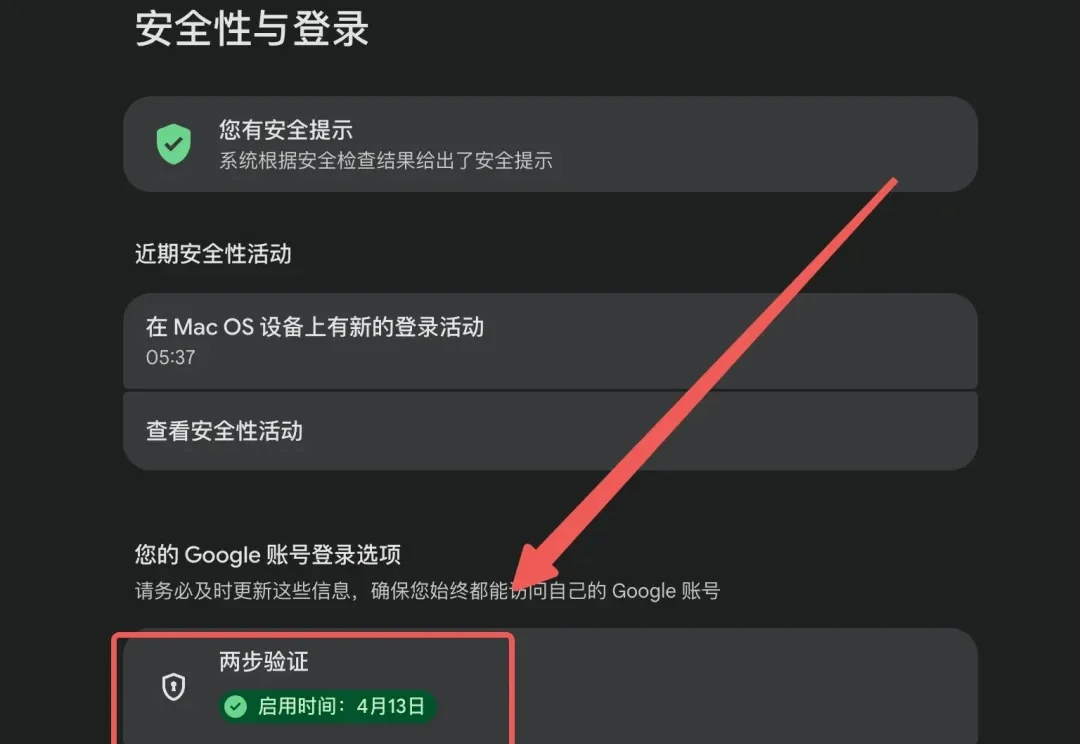
去年带大家靠学生优惠白嫖了一年的 Gemini Pro,前几天发邮件提醒我快到期了。

不出所料,之前爆料的 Gemini Omni 正式发布了。

2026年5月13日,作为每年 Google I/O 的前哨站,同时也是关于最重要的部分——安卓的独立发布会,The Android Show在线上开幕,揭开了 2026 年 Google 在 Android 领域全系产品阵容的新品发布阵容。

Chrome正在把你的电脑变成它的AI算力节点,没问过你,没通知你,而且删了还会自动重下。

今天凌晨,谷歌 Gemini 突然放大招,它在 X 上宣布:现在 Gemini 可以直接生成PDF、Word、Excel 或 Google Workspace 等文件,无需上传模板,只用和Gemini交流要做什么和讲清文件格式。
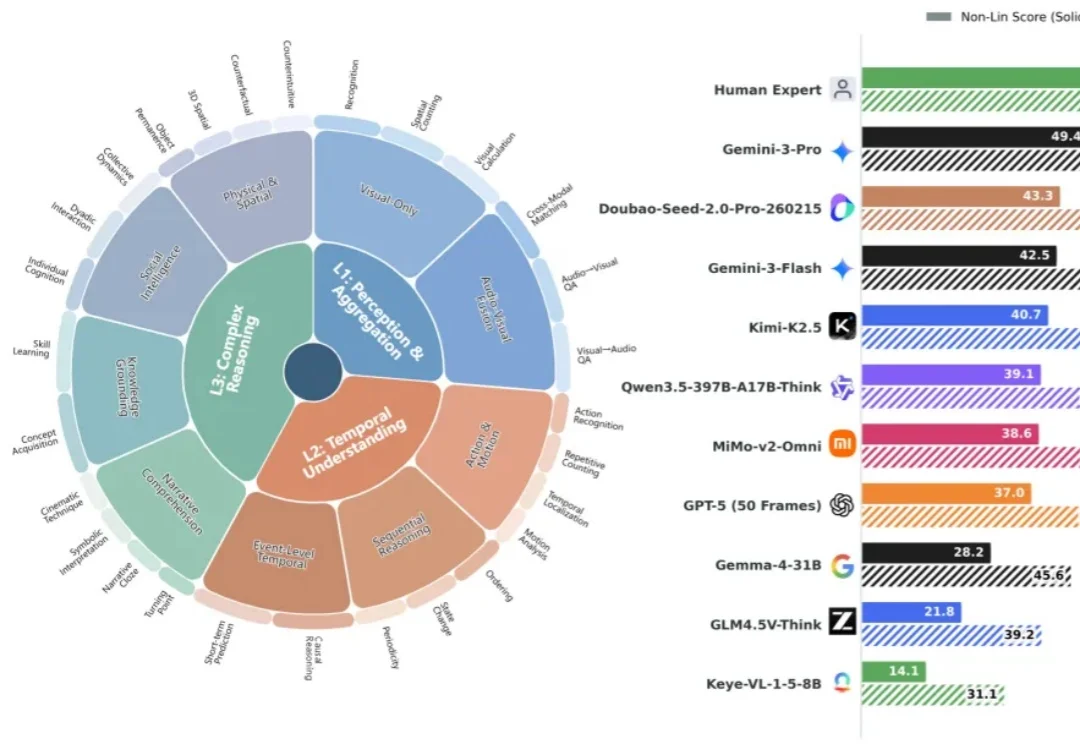
现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在 Google Gemini 评测团队邀约下推出视频理解新基准 Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及 3300 + 人工时高质量标注,揭示模型与人类的巨大鸿沟(49 vs 90)、传统 Acc 指标虚高、以及 “Thinking” 并非总是增益等现象。